

A 3D model of a sitting area. Environmental spatial similarity could help an AI recognize the objects in a setting like this more easily. Adobe Stock: 371561612
Environmental Spatial Similarity Approach with Bridges-2 Improves Speed and Accuracy for More Flexible Visual, General AI Learning
Current artificial intelligence (AI) visual recognition learns the difference between objects using a huge data set in which humans have labeled what’s what. Scientists at the Pennsylvania State University have taken a page from how human toddlers learn, using PSC’s flagship Bridges-2 to help an AI algorithm recognize objects using a simulated space it can “explore.” This environmental spatial similarity (ESS) approach proved superior to current methods in recognizing objects with a smaller, unlabeled data set, and could be a springboard to AIs capable of much more flexibility, particularly in roles that would put humans at an unacceptable risk.
WHY IT’S IMPORTANT
One of the problems with artificial intelligence is that it isn’t “intelligent” in the way that people normally think of the word. Thanks to a kind of cheat sheet consisting of billions of labeled images, a computer program can, through the brute force of guessing and then correcting itself when it’s wrong, train itself to tell the difference between a chair and a table reliably. But it doesn’t actually “know” what it’s doing. It’s just learned the odds.
Compare that with a toddler. She crawls around her (child proofed!) room looking at things from different angles. She’s thinking about what she’s seeing and how her position in space makes the same objects look different. Thanks to that more sophisticated way of learning, she can figure out a chair is different than a table using far fewer examples, and without anybody telling her, “This is a chair. This is a table.” And she understands that difference in a physical way that the computer doesn’t.
“Currently, many large-language models are using supervised learning. But those kind of models need a lot of input data, which is a much larger amount than two-year-old children can get … [We thought that] maybe, if we can get some knowledge from the infants, [we could design] a visual learning process that might help those models to learn better. — Lizhen Zhu, Penn State
Today’s technology isn’t anywhere near being able to simulate a human mind in silicon. But psychology researchers at Penn State wondered whether you could up the AI’s game by taking a page from the toddler’s way of learning. If you gave the AI a spatial sense of objects and where they are, can it use those different perspectives to learn more efficiently? Such an AI would be invaluable in jobs as diverse as a small robot searching a collapsed building for human survivors or a rover exploring an alien planet, particularly in situations where learning has to be rapid, power must be conserved, or humans would be at too much risk.
To tackle this problem, an interdisciplinary team was formed with experience in both psychology and AI. Lizhen Zhu, a graduate student studying with Distinguished Professor of Information Sciences and Technology James Z. Wang at Penn State, took on the challenge. Her tool of choice for the project was PSC’s flagship Bridges-2 supercomputer.
HOW PSC HELPED
Contrastive learning is a common technique used to train AIs without having to label what is what in the images. While it works well and makes the human labor of labeling objects unnecessary, it is hard. It takes billions of images, which are difficult to get in the first place. Also, the multiple petabytes of storage it requires restricts the work to only the largest computing facilities. It is also enormously expensive in the energy it burns up. Lizhen wanted to see if she could use the example of the toddler’s learning process to bring the number of images needed down from billions to the millions that a child would encounter.
Coupling unlabeled objects with a simulated environment that allows the AI to learn by running an agent — much like in a first-person video game — as it views objects from different angles could possibly be cheaper, faster, and more adaptable to new tasks. Such a pretext task, in which the AI in effect learns how to learn via spatial relationships, could be quite different than the downstream classification task you actually need to accomplish.
“There are two separate steps. First, we need to get our data set … We control an avatar exploring a 3D environment, and then collect the images as well as the rotations and the positions … And then we use that data set to train the [contrastive learning] model, and that calculation is running on Bridges-2.” — Lizhen Zhu, Penn State
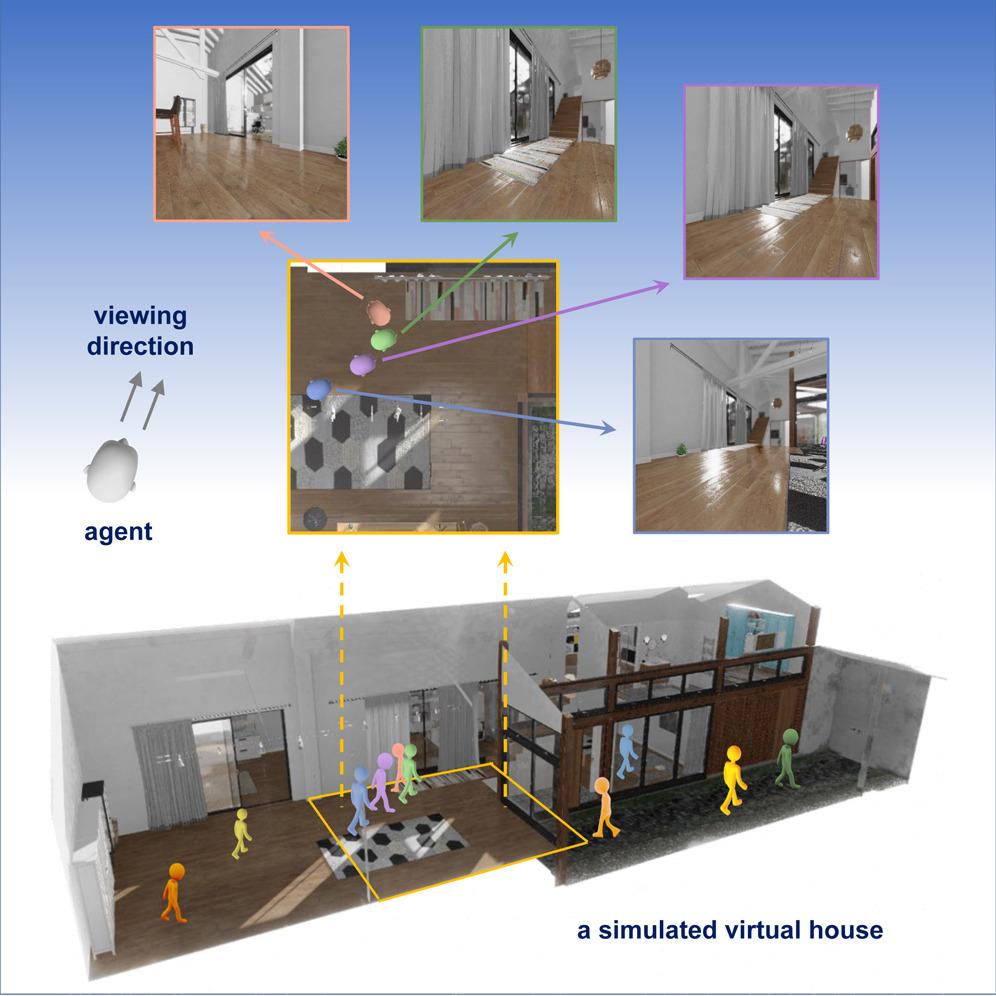 The trick was that the AI would have to compare dozens of parameters — think of things like relative position/rotation, lighting angle, and the focal length of a given view — against each other many times over. The task would require many graphics processing units (GPUs), which, initially developed for rendering images in video games, excel at such comparisons. The National Science Foundation-funded Bridges-2, with 280 late-model GPUs, offered much-needed power in processing these comparisons in a reasonable amount of time. The scientists got time on Bridges-2 via an allocation from ACCESS, the NSF’s network of supercomputing resources, in which PSC is a leading member.
The trick was that the AI would have to compare dozens of parameters — think of things like relative position/rotation, lighting angle, and the focal length of a given view — against each other many times over. The task would require many graphics processing units (GPUs), which, initially developed for rendering images in video games, excel at such comparisons. The National Science Foundation-funded Bridges-2, with 280 late-model GPUs, offered much-needed power in processing these comparisons in a reasonable amount of time. The scientists got time on Bridges-2 via an allocation from ACCESS, the NSF’s network of supercomputing resources, in which PSC is a leading member.
Running on Bridges-2, the Penn State team’s ESS approach performed similarly to traditionally trained AIs in learning and correctly identifying objects from unlabeled data — but it did so much more quickly and with far less input data. Better, a relatively small amount of additional data improved its performance far out of proportion to the data volume — a little more like a toddler than a traditional AI. Best, the ESS-trained AI proved particularly good at dealing with unfamiliar environments.
“I think if we didn’t have access to Bridges-2, we wouldn’t have been able to do all these experiments … it would have taken us years of time rather than months of time.” — James Z. Wang, Penn State
Lizhen’s ESS work promises progress in more than just visual learning by AIs — it potentially advances the ability of systems to learn from their environments in general and directly, without human intervention. The scientists reported these proof-of-concept findings, with Zhu as first author, in the journal Patterns in May 2024.